It was 2 AM, and I was staring at my screen, exhausted. I had 12 client websites to crawl, each requiring four different Screaming Frog exports—URLs, images, issues, and an overview. That meant nearly 50 files to generate and compile into Excel reports, all before morning.
Manually running Screaming Frog’s GUI for each site was painfully slow and inefficient. I needed automation. That’s when I turned to Screaming Frog CLI.
With a single command, I automated the entire process, saving hours of tedious work.
Why Use Screaming Frog CLI Instead of the GUI?
The Screaming Frog SEO Spider is well known for its powerful crawling capabilities, but the command-line interface (CLI) version takes automation and scalability to the next level. With the CLI, you can:
- Schedule automated crawls using cron jobs or Windows Task Scheduler
- Run multiple crawls simultaneously without relying on a GUI session
- Extract specific data using command-line parameters
- Integrate Screaming Frog with other tools, such as Google Sheets, APIs, and Python scripts
- Save system resources compared to running multiple GUI instances
For SEO professionals handling large-scale audits, CLI provides a more efficient workflow, allowing you to focus on analysis rather than manual execution.
Getting Started with Screaming Frog CLI
Before running Screaming Frog from the command line, ensure you have the latest version installed. Then, you can execute commands via the terminal (macOS/Linux) or Command Prompt (Windows).
First, you’ll need to download Screaming Frog from the official site and have a terminal ready. Once these are prepared, let’s begin.
Basic Usage
Here’s a basic Screaming Frog CLI command:
/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher --headless \
--crawl https://example.com \
--save-report "Crawl Overview" \
--output-folder "$HOME/Desktop/"
This command launches Screaming Frog in headless mode (without the UI), starts crawling the specified URL (--crawl), selects which reports to export (--save-report), and saves them in the defined output folder (--output-folder).
The simplest usage works like this:
- First line launches the SF Launcher in headless mode
- Second line specifies the URL to crawl
- Third line indicates what information we want
- Fourth line defines where to save the data
It’s that simple. Now you can change the domain (URL) in this command to get the data you need and use it in Excel.
Intermediate Usage
Let’s first add an alias for the Screaming Frog Launcher. From now on, we’ll use just the sf shortcut to access the headless Screaming Frog CLI:
For Mac:
echo 'alias sf="/Applications/Screaming\ Frog\ SEO\ Spider.app/Contents/MacOS/ScreamingFrogSEOSpiderLauncher"' >> ~/.zshrc;
source ~/.zshrc
For Windows:
ScreamingFrogSEOSpiderCli.exe
For Linux:
screamingfrogseospider
Overview of the CLI
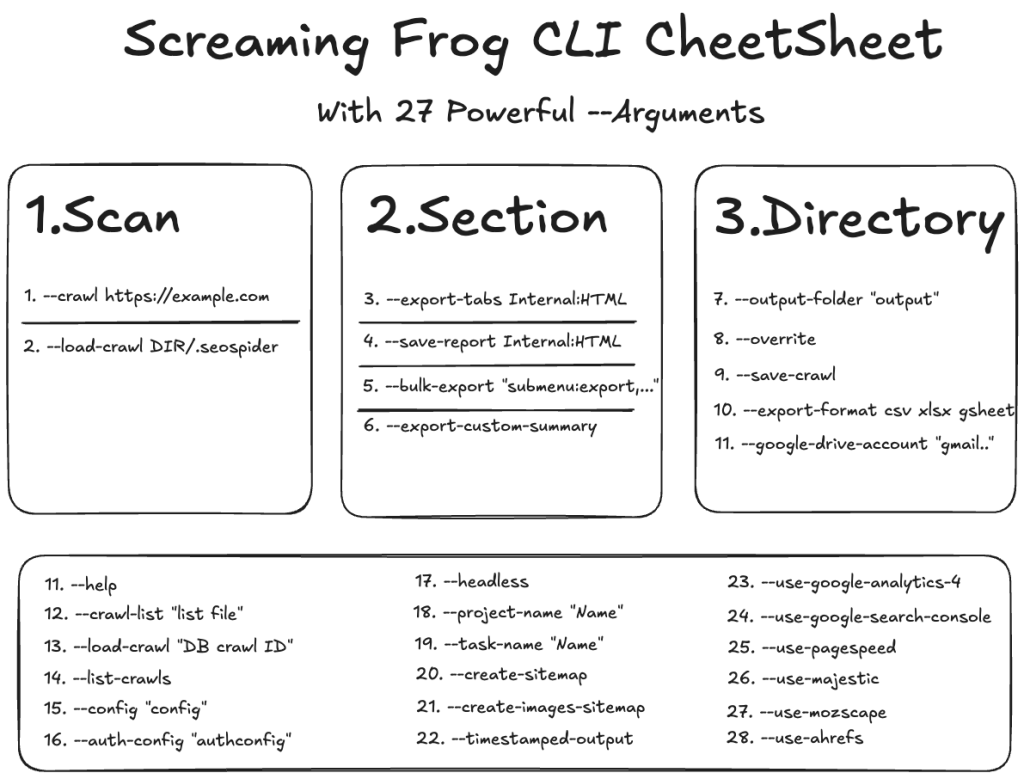
Now that we’ve created our alias for the terminal, we no longer need to add the entire CLI path each time. Before we dive into all CLI arguments, let’s take a bird’s-eye view of everything.
The CLI requires three main argument groups to function:
- Scan Source – Website URL
- Section – Part to be saved
- Directory – Where to save
Almost all arguments are grouped under these three categories.
Scan Source: Crawl or Load Source
--crawl: You need to write your URL right after this. Don’t forget to add https: before your domain, for example https://example.com
--load-crawl: You can enter a previously saved .seospider extension file. Either the crawl or load-crawl argument is mandatory for the CLI to work.
Choose Section for Desired Data
Now we’ve reached the most important part. We’ve scanned our site and have all the data via CLI, but which ones do we want to export? The answer lies in the following four arguments:
--export-tabs "tab:filter,..."
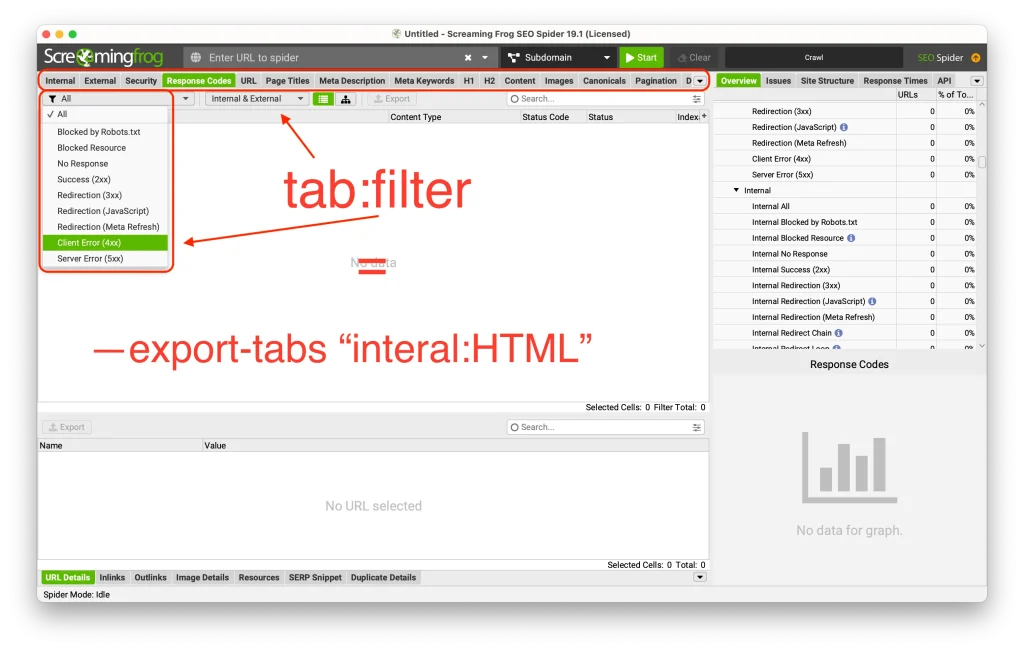
--export-tabs – Allows us to access the main area tabs on the Screaming Frog screen. We can select multiple with tab:filter pairs.
sf --headless --crawl https://example.com --export-tabs "Internal:All,Images:All" --output-folder "$HOME/Desktop/" --overwrite
Some of the available tabs include:
- AMP:All
- Analytics:All
- Canonicals:All
- Content:All
- External:All
- H1:All
- Images:All
- Internal:All
- Meta Description:All
- Page Titles:All
- Response Codes:All
- URL:All
To see all filters, you can use this command:
sf --help export-tabs--save-report "submenu:report,..."
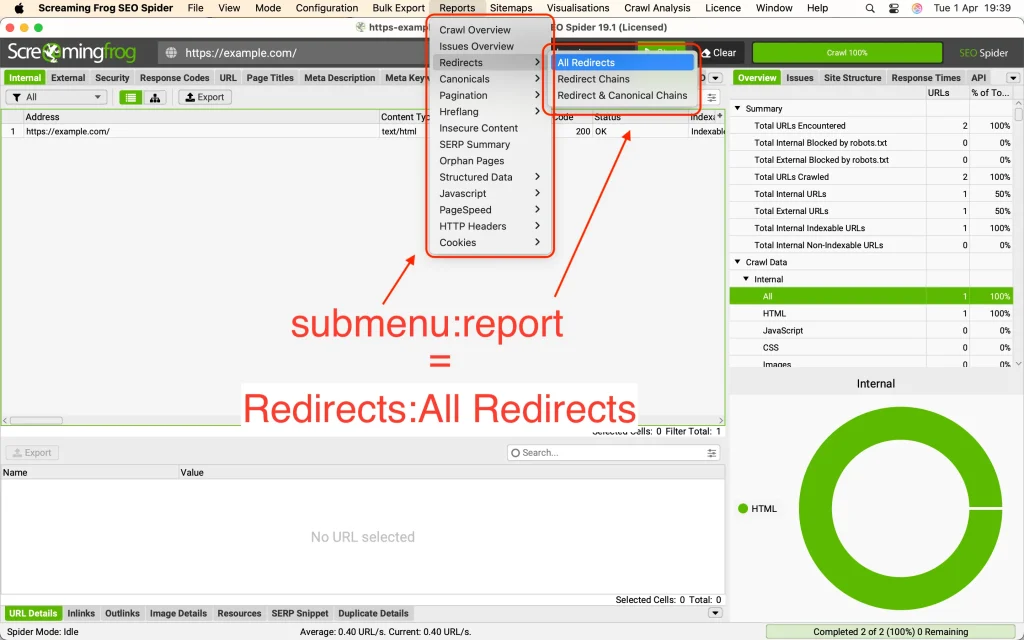
With this argument, we can select reports corresponding to the Reports menu in the UI.
sf --headless --crawl https://example.com \
--export-tabs "Internal:All,Images:All" \
--output-folder "$HOME/Desktop/" --overwrite \
--save-report "Crawl Overview,Canonicals:Canonical Chains"
Some of the submenu and report options include:
- Crawl Overview
- Issues Overview
- Redirects:All Redirects
- Canonicals:Canonical Chains
- SERP Summary
- Orphan Pages
- PageSpeed:Avoid Large Layout Shifts
To see all save-report options in your terminal:
sf --help save-report--bulk-export "submenu:export,..."
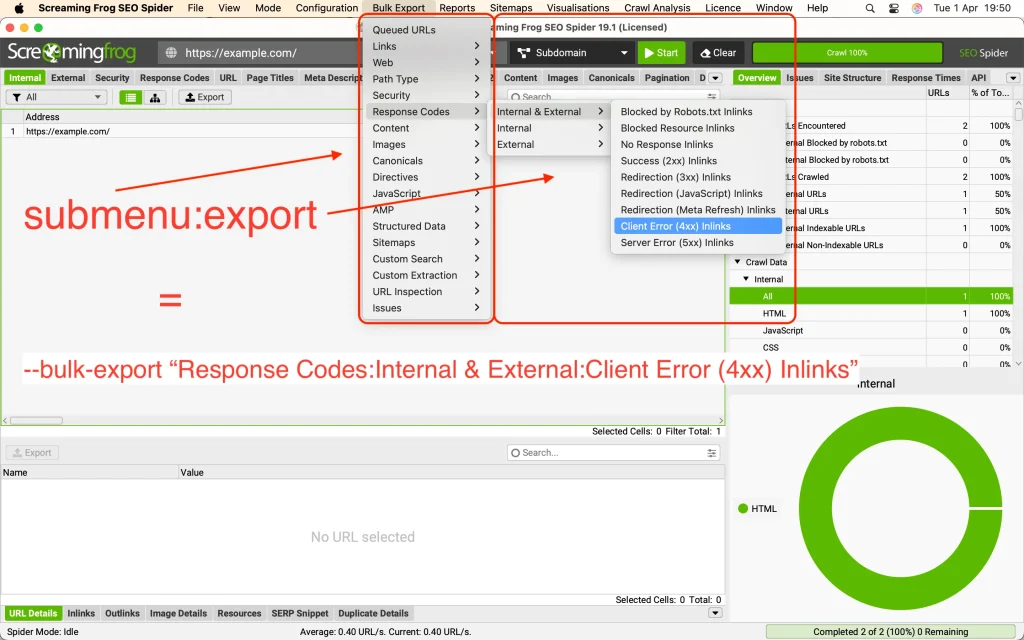
With this argument, we can select files corresponding to the Bulk Export menu in the UI.
sf --headless --crawl https://example.com \
--output-folder "$HOME/Desktop/" --overwrite \
--bulk-export "Response Codes:Internal & External:Client Error (4xx) Inlinks"
Submenus include:
- Links
- Response Codes
- Content
- Images
- Canonicals
- Structured Data
- Issues
To see all bulk export options in your terminal:
sf --help bulk-export--export-custom-summary "item 1,item 2, item 3..."
Similarly, you can access all custom summary options.
To list the same data in your terminal:
sf --help export-custom-summaryChoose Directory to Export Files
Now we come to the last argument group: where to save!
There are two commands here. You can use both at the same time. For saving as a local file, use the output directory argument:
--output-folder "$HOME/Desktop/" --overwriteAnd to save to your Google Drive:
--google-drive-account "google account"All options you select will be saved as files in the location you specify.
--overwrite: If you have a file with the same name in the specified folder, for example internal_all.csv, your command will give an error. I recommend using this command to overwrite.
--export-format csv xls xlsx gsheet: You can select the format of your file(s) with this option. csv is selected by default.
--timestamped-output: Creates a timestamped folder in your local and Google Drive. A good option to prevent your files from getting mixed up.
Other Commands
We’ve examined the CLI of Screaming Frog SEO Spider Crawler for more effective use, but it’s worth mentioning some other commands.
--help: Lists all options.
--config "config": Will work using custom configuration if any.
API Access
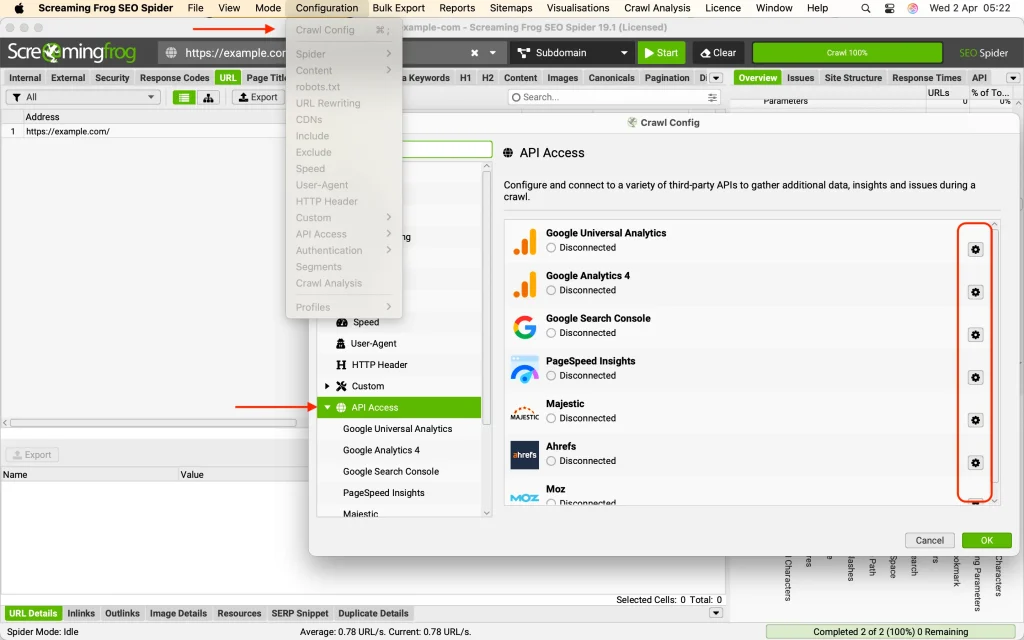
You can also take advantage of other tools for the pages you’ll crawl. To do this, simply click on the settings icon of each one and authenticate as needed.
And you can use the service you want with the following options:
--use-google-search-console
--use-pagespeed
--use-majestic
--use-mozscape
--use-ahrefs
--use-google-analytics
--use-google-analytics-4
Other Arguments
The remaining arguments are:
--crawl-list "list file"
--load-crawl "database crawl ID"
--list-crawls
--auth-config "authconfig"
--project-name "Name"
--task-name "Name"
--create-sitemap
--create-images-sitemap
Advanced Use Cases
Beyond basic crawling, Screaming Frog CLI allows you to:
Check Core Web Vitals using Lighthouse integration:
screamingfrogseospider --crawl https://example.com --lighthouse
Validate structured data:
screamingfrogseospider --crawl https://example.com --structured-data
Compare historical crawl data for SEO audits:
screamingfrogseospider --compare ./old_crawl.seospider ./new_crawl.seospider
Automating Screaming Frog with a Cron Job
For regular monitoring, set up a scheduled crawl. On Linux/macOS, add the following to crontab:
0 3 * * * screamingfrogseospider --crawl https://example.com --headless --output-folder /reports/
This command runs a crawl daily at 3 AM and stores reports in the /reports/ directory.
How Our SEO Services Can Help
Understanding and utilizing Screaming Frog’s CLI can significantly improve your website’s SEO, but knowing how to interpret and act on this data is where expertise matters. Our SEO services specialize in technical audits, ranking improvements, and solving complex indexing issues. Whether you need a one-time deep crawl analysis or ongoing monitoring, we provide data-driven insights to boost your search performance.
We leverage automation and advanced SEO strategies to ensure your website stays ahead in competitive search landscapes. If your site has been hit by an algorithm update, struggling with JavaScript rendering, or losing organic visibility, we can diagnose the issue and implement the right fixes.
Conclusion
Screaming Frog’s CLI is a game-changer for SEOs and developers who need efficiency, automation, and deep data extraction. By integrating it into your workflow, you can conduct large-scale crawls, schedule automated audits, and extract precise insights without the hassle of manual execution. Are you ready to take your SEO audits to the next level with automation?